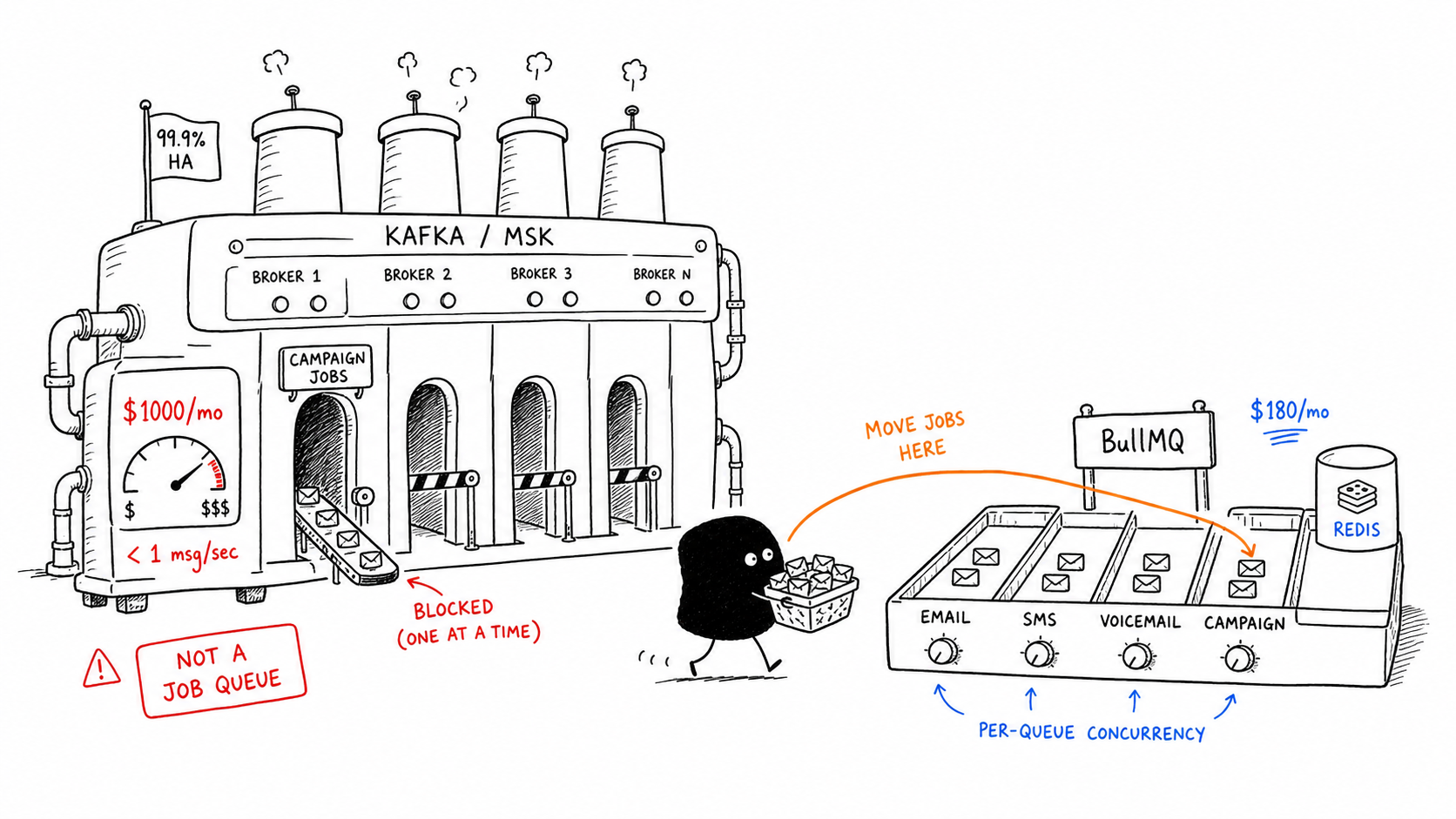
$1000/month. AWS MSK. ten users.
thats not a scaling problem. thats a miscalculation.
a client was running outbound campaigns for sales teams: emails, sms, voicemail. a few thousand messages a day, spread across 9am to 8pm EST. and they had kafka sitting in the middle of it all. a distributed log built to handle trillions of events at linkedin, doing the job that redis was born to do.
i got called in to look at their infra. a week later, kafka was gone. bill dropped to $180. nothing broke. campaigns actually got faster.
what they were building
the product is simple. a user creates a campaign (a sequence of touches across email, sms, voicemail) targeted at a contact list. they hit launch. between 9am and 8pm, the system fans it out to every contact, respects step delays, and delivers through the right channel.
two services. an api that takes the launch request. a worker that does the actual scheduling and sending.
kafka was the bridge between them:

decoupled services. durable log. the whole “event-driven architecture” pitch. on paper, fine.
in reality, two things were quietly killing them.
why kafka in the first place
honest answer: it felt like the serious choice.
they were building a system that sends messages at scale: campaigns, sequences, multi-channel delivery. every architecture post you read for something like this says “use an event-driven system.” kafka is the name that keeps coming up. it’s what the big companies use. it looked like the right foundation to grow into.
there was also a real technical reason. the api and worker are separate services. they needed something in between to handle the handoff: take a launch request, queue the work, let the worker pick it up asynchronously. kafka fit that description. it gave decoupling, async processing, and replay if something went wrong.
what they didnt think hard enough about: kafka solves those problems at a scale they didnt have, with guarantees they didnt need, at a cost that made no sense for where they were. they reached for it because it was familiar from blog posts, not because they had the problems it was built for.
thats the trap. kafka is well-documented, heavily discussed, and genuinely impressive engineering. so it feels responsible to use it. it isnt, until you actually need it.
why kafka was the wrong call
it made campaigns serial
one topic. one consumer group. campaigns processed in order.
that’s the kafka model. and its the right model when ordering matters across related events. but their jobs werent related. campaign A has nothing to do with campaign B. there’s no reason campaign B should wait for campaign A’s 500 contacts to finish before it even starts.
but thats exactly what happened. a user launched a big campaign. the worker chewed through it. another user launched theirs. it sat there. completely blocked until the first one was done.
you can throw more consumers at this. more consumers means more MSK throughput, which means more brokers, which means a bigger bill. they were already on the smallest possible MSK cluster and it was $1000/month. scaling up wasnt an option. scaling up was the problem.
the bill made no sense
and the numbers:
| metric | their scale |
|---|---|
| active users | ~10 |
| campaigns in flight | ~100 |
| total contacts | 100,000 |
| messages per day | 1,000–4,000 |
| peak msgs/sec | < 1 |
under one message per second at peak. a single redis instance doesnt even blink at that. kafka’s pricing model is built around brokers running 24/7, replicating partitions across availability zones, holding data for days. you pay for all of that whether you use a byte of it or not.
they had a job queue. they just kept calling it an event stream.
what replaced it
we deleted kafka and put BullMQ on Redis in its place. one queue per type of work, not one queue for everything.

per-queue concurrency
seven queues total. each with its own worker. each with its own concurrency:
export const WORKER_CONCURRENCY = {
[JobType.CAMPAIGN]: 100,
[JobType.CAMPAIGN_STEP]: 40,
[JobType.EMAIL]: 30,
[JobType.SMS]: 50,
[JobType.VOICEMAIL]: 1,
[JobType.WATCH]: 100,
[JobType.EMAIL_SENDER_WARMUP]: 1,
};voicemail is 1 because twilio rate limits and burning voice minutes in parallel is expensive. email is 30 because sendgrid handles it fine. watch is 100 because its just a webhook poll, cheap and fast. each queue is tuned independently. with kafka, that kind of parallelism costs money. with BullMQ, its a number in a config file.
api talks directly to redis
the api now adds jobs directly to redis. no broker in between:
const queue = QueueManager.getInstance().getQueue<CampaignJob>('CAMPAIGN');
await queue.add('launch', { campaignId, userId }, { jobId: idempotencyKey });the worker picks it up in milliseconds. the api and worker are owned by the same team, deployed together, change together. the broker wasnt decoupling two organizations. it was just latency and money between two processes that wanted to talk.
the cost
cost breakdown:
| monthly | |
|---|---|
| before (AWS MSK) | ~$1,000 |
| after (Redis) | ~$180 |
| saved | $820/mo |
$10,000/year. the migration took a week. ten users, so we scheduled an hour of downtime and cut over. the migration was cheaper than one month of MSK.
”but what about durability”
durability
Redis with AOF persistence covers durability for job state. BullMQ stores every job: data, attempts, failures, result. if a worker crashes mid-job, BullMQ marks it stalled and another worker picks it up. they havent lost a job since the migration.
replay
for replay we integrated Bull Board , a UI that sits on top of BullMQ and shows every queue, every job, every state. failed job? click retry. want to know why it failed? click it and read the logs. want to see how far a running campaign has progressed? the percentage is right there.
createBullBoard({
queues: [
new BullMQAdapter(createQueueMQ('EMAIL', redisConnection)),
new BullMQAdapter(createQueueMQ('VOICEMAIL', redisConnection)),
new BullMQAdapter(createQueueMQ('WATCH', redisConnection)),
new BullMQAdapter(createQueueMQ('CAMPAIGN', redisConnection)),
new BullMQAdapter(createQueueMQ('CAMPAIGN_STEP', redisConnection)),
new BullMQAdapter(createQueueMQ('SMS', redisConnection)),
],
serverAdapter,
});what they lost: completed jobs get cleaned up after 24 hours. if you need a permanent audit trail you log to a database, which they already do anyway. kafka wasnt replacing that. it was sitting on top of it.
the assumption most people make is that kafka’s log is the audit trail. its not. its a buffer with a retention window. if you need history, you need a database. if you need replay, you need a dashboard. kafka gives you neither. it gives you a stream you have to build both of those things on top of.
when kafka is the right call
kafka is the right tool when multiple independent consumers need the same event stream: analytics, billing, search indexing, an ML pipeline all reading the same events at their own pace. thats what it was built for.
or when you need strict ordering across a high-throughput stream of related events. trading systems. CDC pipelines. per-user activity feeds at real scale.
or when youre moving thousands of events per second sustained, not thousands per day.
or when separate teams own separate services and need a contract between them that isnt a synchronous API.
none of those described this client. they didnt need kafka. they needed a job queue. BullMQ, Sidekiq, RQ, Celery, SQS. all valid answers. all cost a fraction of what kafka costs. all easier to operate. all give you the things you actually want without the broker fleets, partition math, and consumer group rebalancing you dont.
why is this even a debate?? kafka has a specific job. a job queue has a different specific job. using kafka as a job queue at early scale is just paying for complexity you dont need.
if they outgrow BullMQ, the migration will be a real engineering project. by then theyll have the revenue to pay for it. until then, every “future-proof” choice is a tax you pay every month for a future that hasnt arrived.
they paid $820/month for over a year before we fixed it. damm.